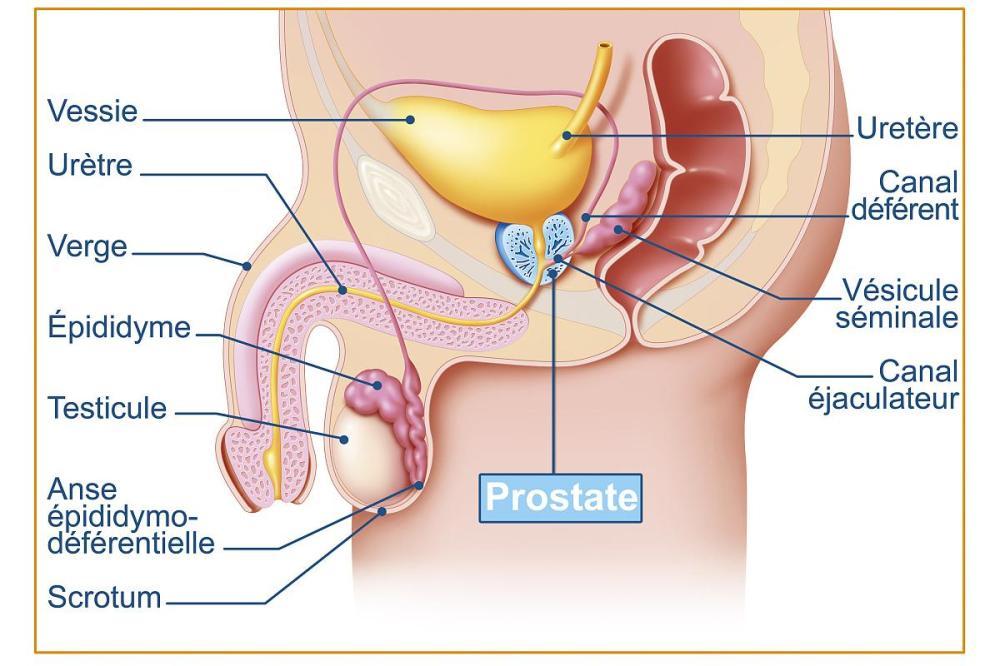
簡介
邊界點是數據集中一類有着特殊意義的數據對象。它們位于基于密度的簇的邊沿區域。邊界點處理在數據挖掘技術中有重要意義,它們代表了一類歸屬并不明确的個體,如果單純地依靠某種方法把其歸類到一個特定的簇中,其效果往往适得其反。
邊界點不同于孤立點和噪聲點。孤立點是一類在統計上處于少數地位的對象,噪聲點是一類對統計産生幹擾或者偏離一定分布的對象,它們通常位于數據空間的低密區域中,而邊界點則不同,它們是數據空間中處于高密區域邊沿的一類數據對象,它們的一側是高密區域,一側是相對的低密區域。
聚類技術的研究是近幾年研究的一個熱點,已經提出的許多聚類算法,但是,對聚類邊界模式的探讨還不多。聚類的邊界點是指位于高密聚類邊沿的一類數據對象,它代表了遊離在兩個或多個類别之間的一類個體對象,其歸屬并不明确,它們常常具有兩個或兩個以上的聚類特征。邊界點研究有着重要的應用價值。
定義
Chen Xia等提出了聚類邊界點檢測算法BORDER,其邊界點的定義如下:
邊界點(Boundary point):一個邊界點p是指滿足下列兩個條件的數據對象:
(1)它位于一個高密的區域IR;
(2)p的附近存在一個區域IR’,Density(IR)>Density(IR’),或者
Density(IR)
聚類的邊界代表了一種潛在的模式,對數據挖掘的着重要的意義。但是目前涉及的邊界的算法并不多,對其的研究遠遠不夠。
在DBSCAN算法中,提到邊界點(Border Points):一個非核心點對象,如果其落在某核心點的Eps-鄰域内,則稱之為邊界點。一個邊界點可能同時落入一個或多個核心點的Eps-鄰域。
數學中的邊界點:
同濟大學高數六版釋義:如果點P的任一鄰域内既含有屬于E的點,又含有不屬于E的點,則稱P為E的邊界點。
研究
根據孤立點是數據集合中與大多數數據的屬性不一緻的數據,邊界點是位于不同密度數據區域邊緣的數據對象,提出了基于相對密度的孤立點和邊界點識别算法(OBRD)。
該算法判斷一個數據點是否為邊界點或孤立點的方法是:将以該數據點為中心、r為半徑的鄰域按維平分為2個半鄰域,由這些半鄰域與原鄰域的相對密度确定該數據點的孤立度和邊界度,再結合阈值作出判斷。
實驗結果表明,該算法能精準有效地對多密度數據集的孤立點和聚類邊界點進行識别。