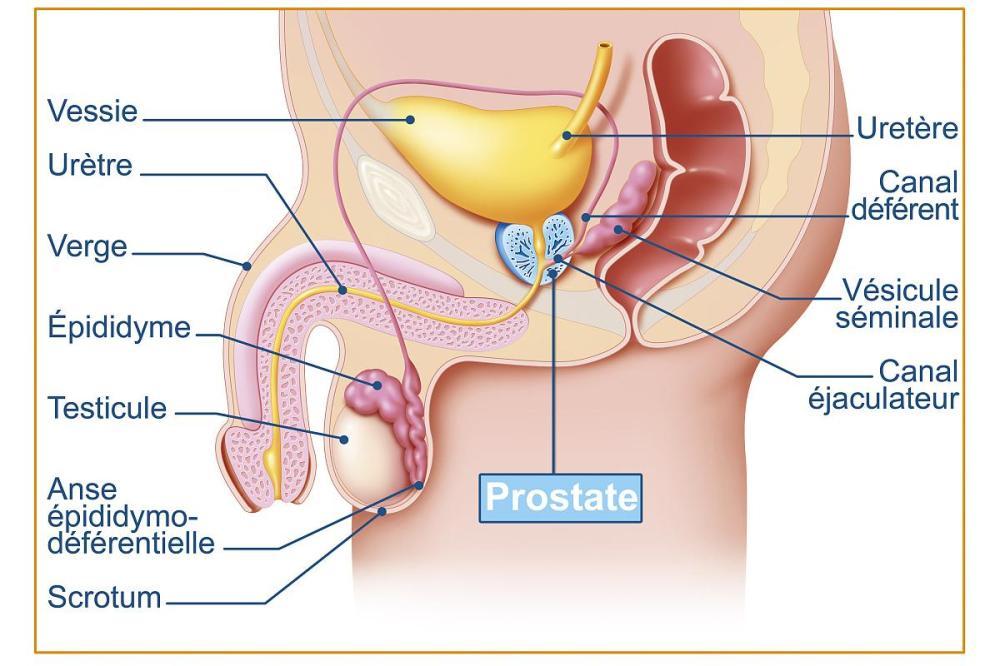
简介
边界点是数据集中一类有着特殊意义的数据对象。它们位于基于密度的簇的边沿区域。边界点处理在数据挖掘技术中有重要意义,它们代表了一类归属并不明确的个体,如果单纯地依靠某种方法把其归类到一个特定的簇中,其效果往往适得其反。
边界点不同于孤立点和噪声点。孤立点是一类在统计上处于少数地位的对象,噪声点是一类对统计产生干扰或者偏离一定分布的对象,它们通常位于数据空间的低密区域中,而边界点则不同,它们是数据空间中处于高密区域边沿的一类数据对象,它们的一侧是高密区域,一侧是相对的低密区域。
聚类技术的研究是近几年研究的一个热点,已经提出的许多聚类算法,但是,对聚类边界模式的探讨还不多。聚类的边界点是指位于高密聚类边沿的一类数据对象,它代表了游离在两个或多个类别之间的一类个体对象,其归属并不明确,它们常常具有两个或两个以上的聚类特征。边界点研究有着重要的应用价值。
定义
Chen Xia等提出了聚类边界点检测算法BORDER,其边界点的定义如下:
边界点(Boundary point):一个边界点p是指满足下列两个条件的数据对象:
(1)它位于一个高密的区域IR;
(2)p的附近存在一个区域IR’,Density(IR)>Density(IR’),或者
Density(IR)
聚类的边界代表了一种潜在的模式,对数据挖掘的着重要的意义。但是目前涉及的边界的算法并不多,对其的研究远远不够。
在DBSCAN算法中,提到边界点(Border Points):一个非核心点对象,如果其落在某核心点的Eps-邻域内,则称之为边界点。一个边界点可能同时落入一个或多个核心点的Eps-邻域。
数学中的边界点:
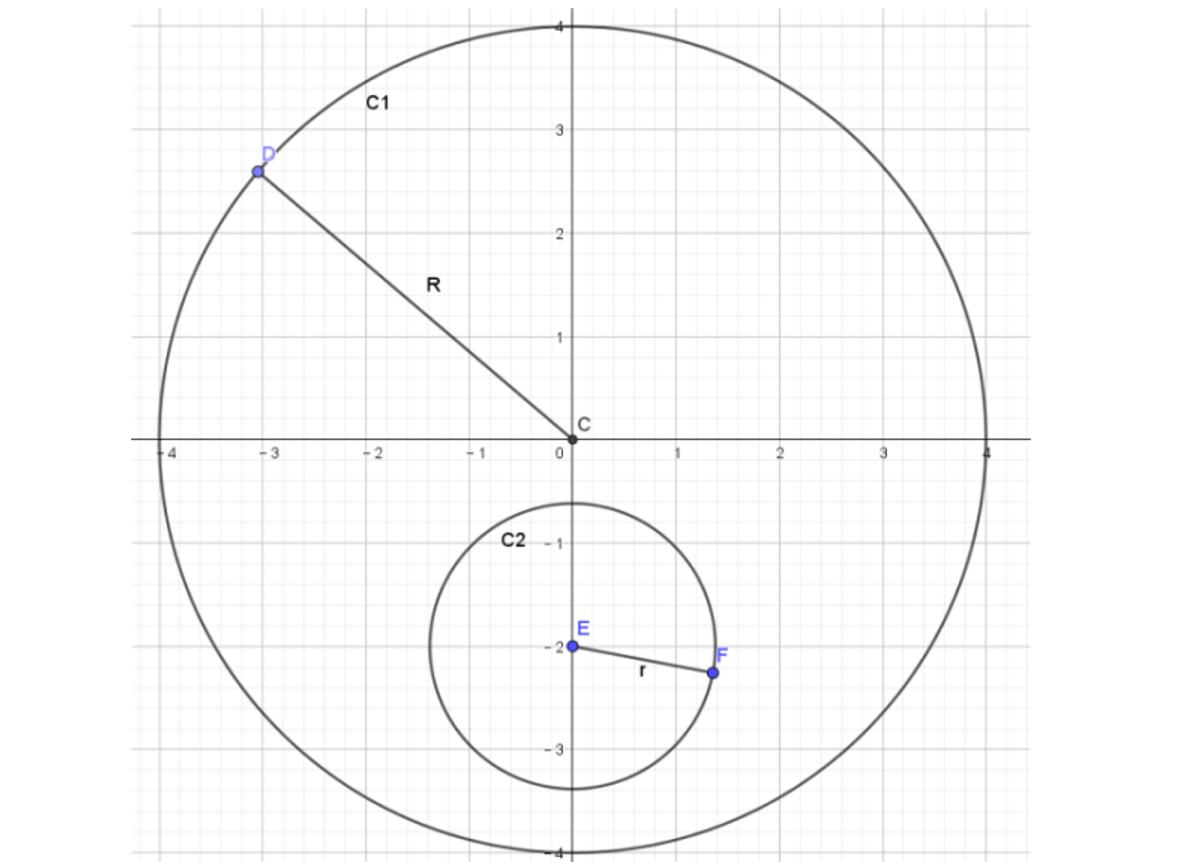
同济大学高数六版释义:如果点P的任一邻域内既含有属于E的点,又含有不属于E的点,则称P为E的边界点。
研究
根据孤立点是数据集合中与大多数数据的属性不一致的数据,边界点是位于不同密度数据区域边缘的数据对象,提出了基于相对密度的孤立点和边界点识别算法(OBRD)。
该算法判断一个数据点是否为边界点或孤立点的方法是:将以该数据点为中心、r为半径的邻域按维平分为2个半邻域,由这些半邻域与原邻域的相对密度确定该数据点的孤立度和边界度,再结合阈值作出判断。
实验结果表明,该算法能精准有效地对多密度数据集的孤立点和聚类边界点进行识别。