简介
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
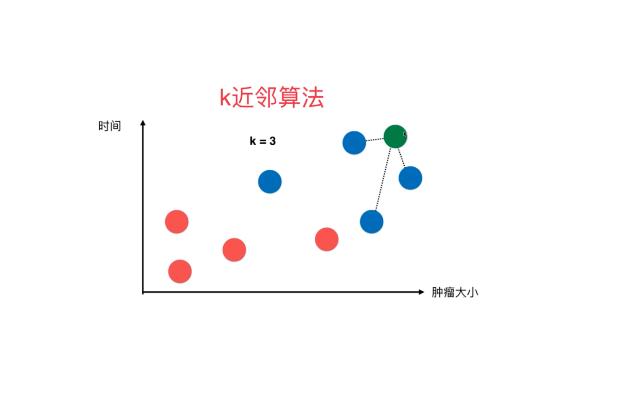
该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类。
该方法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最邻近点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。另外还有一种 Reverse KNN法,它能降低KNN算法的计算复杂度,提高分类的效率。
KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
核心思想
KNN算法的核心思想是,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。KNN方法在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
算法流程
总体来说,KNN分类算法包括以下4个步骤:
①准备数据,对数据进行预处理 。②计算测试样本点(也就是待分类点)到其他每个样本点的距离。③对每个距离进行排序,然后选择出距离最小的K个点 。④对K个点所属的类别进行比较,根据少数服从多数的原则,将测试样本点归入在K个点中占比最高的那一类。
优点
KNN方法思路简单,易于理解,易于实现,无需估计参数 。
缺点
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点 。
改进策略
目前对KNN算法改进的方向主要可以分为4类:
一是寻求更接近于实际的距离函数以取代标准的欧氏距离,典型的工作包括 WAKNN、VDM;
二是搜索更加合理的K值以取代指定大小的K值典型的工作包括SNNB、 DKNAW ;
三是运用更加精确的概率估测方法去取代简单的投票机制,典型的工作包括 KNNDW、LWNB、 ICLNB;
四是建立高效的索引,以提高KNN算法的运行效率,代表性的研究工作包括 KDTree、 NBTree。还有部分研究工作综合了以上的多种改进方法。