簡介
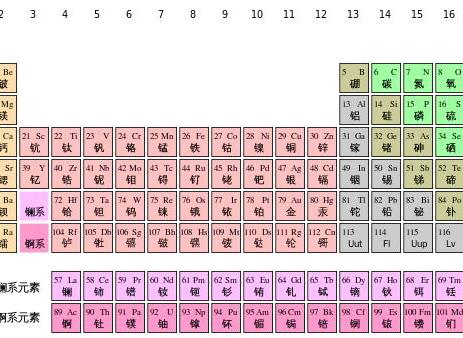
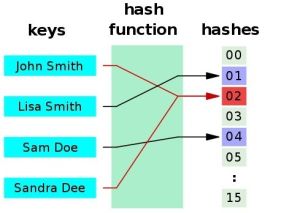
若結構中存在和關鍵字K相等的記錄,則必定在f(K)的存儲位置上。由此,不需比較便可直接取得所查記錄。稱這個對應關系f為散列函數(Hash function),按這個事先建立的表為散列表。
對不同的關鍵字可能得到同一散列地址,即key1≠key2,而f(key1)=f(key2),這種現象稱碰撞。具有相同函數值的關鍵字對該散列函數來說稱做同義詞。綜上所述,根據散列函數H(key)和處理沖突的方法将一組關鍵字映象到一個有限的連續的地址集(區間)上,并以關鍵字在地址集中的“象”作為記錄在表中的存儲位置,這種表便稱為散列表,這一映象過程稱為散列造表或散列,所得的存儲位置稱散列地址。
若對于關鍵字集合中的任一個關鍵字,經散列函數映象到地址集合中任何一個地址的概率是相等的,則稱此類散列函數為均勻散列函數(Uniform Hash function),這就是使關鍵字經過散列函數得到一個“随機的地址”,從而減少沖突。
性質
所有散列函數都有如下一個基本特性:如果兩個散列值是不相同的(根據同一函數),那麼這兩個散列值的原始輸入也是不相同的。這個特性是散列函數具有确定性的結果。但另一方面,散列函數的輸入和輸出不是一一對應的,如果兩個散列值相同,兩個輸入值很可能是相同的,但并不能絕對肯定二者一定相等。輸入一些數據計算出散列值,然後部分改變輸入值,一個具有強混淆特性的散列函數會産生一個完全不同的散列值。
典型的散列函數都有無限定義域,比如任意長度的字節字符串,和有限的值域,比如固定長度的比特串。在某些情況下,散列函數可以設計成具有相同大小的定義域和值域間的一一對應。一一對應的散列函數也稱為排列。可逆性可以通過使用一系列的對于輸入值的可逆“混合”運算而得到。
函數
·直接取餘法:f(x):=x mod maxM; maxM一般是不太接近2^t的一個質數。
·乘法取整法:f(x):=trunc((x/maxX)*maxlongIT)mod maxM,主要用于實數。
·平方取中法:f(x):=(x*x div 1000)mod1000000);平方後取中間的,每位包含信息比較多。
構造方法
散列函數能使對一個數據序列的訪問過程更加迅速有效,通過散列函數,數據元素将被更快地定位。
1.直接尋址法:取關鍵字或關鍵字的某個線性函數值為散列地址。即H(key)=key或H(key)=a·key+b,其中a和b為常數(這種散列函數叫做自身函數)
2.數字分析法
3.平方取中法
4.折疊法
5.随機數法
6.除留餘數法:取關鍵字被某個不大于散列表表長m的數p除後所得的餘數為散列地址。即H(key)=key MOD p,p<=m。不僅可以對關鍵字直接取模,也可在折疊、平方取中等運算之後取模。對p的選擇很重要,一般取素數或m,若p選的不好,容易産生同義詞。
算法
(1)MD4
MD4(RFC 1320)是MIT的Ronald L. Rivest在1990年設計的,MD是Message Digest(消息摘要)的縮寫。它适用在32位字長的處理器上用高速軟件實現——它是基于32位操作數的位操作來實現的。
(2)MD5
MD5(RFC1321)是Rivest于1991年對MD4的改進版本。它對輸入仍以512位分組,其輸出是4個32位字的級聯,與MD4相同。MD5比MD4來得複雜,并且速度較之要慢一點,但更安全,在抗分析和抗差分方面表現更好。
(3)SHA-1及其他
SHA1是由NIST NSA設計為同DSA一起使用的,它對長度小于264的輸入,産生長度為160bit的散列值,因此抗窮舉(brute-force)性更好。SHA-1設計時基于和MD4相同原理,并且模仿了該算法。