中心成立建設
參議員Claude Pepper意識到信息計算機化過程方法對指導生物醫學研究的重要性,發起了在1988年11月4日建立國立生物技術信息中心(NCBI)的立法。NCBI是在NIH的國立醫學圖書館(NLM)的一個分支。NLM是因為它在創立和維護生物信息學數據庫方面的經驗被選擇的,而且這可以建立一個内部的關于計算分子生物學的研究計劃。NCBI的任務是發展新的信息學技術來幫助對那些控制健康和疾病的基本分子和遺傳過程的理解。
研究任務
它的使命包括四項任務:
建立關于分子生物學,生物化學,和遺傳學知識的存儲和分析的自動系統
實行關于用于分析生物學重要分子和複合物的結構和功能的基于計算機的信息處理的,先進方法的研究
加速生物技術研究者和醫藥治療人員對數據庫和軟件的使用。
全世界範圍内的生物技術信息收集的合作努力。
NCBI通過下面的計劃來實現它的四項目的:
NCBI有一個多學科的研究小組包括計算機科學家,分子生物學家,數學家,生物化學家,實驗物理學家,和結構生物學家,集中于計算分子生物學的基本的和應用的研究。這些研究者不僅僅在基礎科學上做出重要貢獻,而且往往成為應用研究活動産生新方法的源泉。他們一起用數學和計算的方法研究在分子水平上的基本的生物醫學問題。
這些問題包括基因的組織,序列的分析,和結構的預測。目前研究計劃的一些代表是:檢測和分析基因組織,重複序列形式,蛋白domain和結構單元,建立人類基因組的基因圖譜,HIV感染的動力學數學模型,數據庫搜索中的序列錯誤影響的分析,開發新的數據庫搜索和多重序列對齊算法,建立非冗餘序列數據庫,序列相似性的統計顯著性評估的數學模型和文本檢索的矢量模型。另外,NCBI研究者還堅持推動與NIH内部其他研究所及許多科學院和政府的研究實驗室的合作。
數據庫和軟件
在1992年10月,NCBI承擔起對GenBank DNA序列數據庫的責任。NCBI受過分子生物學高級訓練的工作人員通過來自各個實驗室遞交的序列和同國際核酸序列數據庫(EMBL和DDBJ)交換數據建立起數據庫。同美國專利和商标局的安排使得專利的序列信息也被整合。
GenBank是NIH遺傳序列數據庫,一個所有可以公開獲得的DNA序列的注釋過的收集。GenBank同日本和歐洲分子生物學實驗室的DNA數據庫共同構成了國際核酸序列數據庫合作。這三個組織每天交換數據。
GenBank以指數形式增長,核酸堿基數目大概每14個月就翻一個倍。最近,GenBank擁有來自47,000個物種的30億個堿基。
孟德爾人類遺傳(OMIM),三維蛋白質結構的分子模型數據庫(MMDB),唯一人類基因序列集合(UniGene),人類基因組基因圖譜,分類學浏覽器,同國立癌症研究所合作的癌症基因組剖析計劃(CGAP)。
Entrez是NCBI的為用戶提供整合的訪問序列,定位,分類,和結構數據的搜索和檢索系統。Entrez同時也提供序列和染色體圖譜的圖形視圖。Entrez是一個用以整合NCBI數據庫中信息的搜尋和檢索工具。這些數據庫包括核酸序列,蛋白序列,大分子結構,全基因組,和通過PubMed檢索的MEDLINE。Entrez的一個強大和獨特的特點是檢索相關的序列,結構,和參考文獻的能力。雜志文獻通過PubMed獲得,PubMed是一個網絡搜索界面,可以提供對在MEDLINE上的九百萬雜志引用的訪問,包含了鍊接到參與的出版商網絡站點的全文文章。
BLAST是一個NCBI開發的序列相似搜索程序,還可作為鑒别基因和遺傳特點的手段。BLAST能夠在小于15秒的時間内對整個DNA數據庫執行序列搜索。NCBI提供的附加的軟件工具有:開放閱讀框尋覓器(ORF Finder),電子PCR,和序列提交工具,sequin和BankIt。所有的NCBI數據庫和軟件工具可以從WWW或FTP來獲得。NCBI還有E-mail服務器,提供用文本搜索或序列相似搜索訪問數據庫一種可選方法。
數據庫介紹
下面按照檢索框上的順序分别介紹各數據庫。
●Nucleotide
該數據庫由國際核苷酸序列數據庫成員美國國立衛生研究院GenBank、日本DNA數據庫(DDBJ)和英國Hinxton Hall的歐洲分子生物學實驗室數據庫(EMBL)三部分數據組成。這三個組織聯合組成國際核苷酸序列數據庫協作體,每天交換各自數據庫中的新增序列記錄實現數據共享。其中的序列數據也通過與基因組序列數據庫(GSDB)合作獲取;專利序列數據通過與美國專利與商标局、國際專利局合作獲取。
●Genome
即基因組數據庫,提供了多種基因組、完全染色體、Contiged序列圖譜以及一體化基因物理圖譜。
●Structures
即結構數據庫或稱分子模型數據庫(MMDB),包含來自X線晶體學和三維結構的實驗數據。MMDB的數據從PDB(Protein Data Bank)獲得。NCBI已經将結構數據交叉鍊接到書目信息、序列數據庫和NCBI的Taxonomy中運用NCBI的3D結構浏覽器和Cn3D,可以很容易地從Entrez獲得分子的分子結構間相互作用的圖像。
●Taxonomy
即生物學門類數據庫,可以按生物學門類進行檢索或浏覽其核苷酸序列、蛋白質序列、結構等。
●PopSet
包含研究一個人群、一個種系發生或描述人群變化的一組組聯合序列。PopSet既包含核酸序列數據又包含蛋白質序列數據。
Entrez功能強大,在于它的大多數記錄可相互鍊接,既可在同一數據庫内鍊接,也可在數據庫之間進行鍊接。當運用BLAST軟件比較某氨基酸或DNA序列與庫中其他氨基酸或DNA序列差異即進行相似性檢索時,則會涉及到蛋白質庫或核苷酸庫的庫内鍊接。庫間鍊接發生在核苷酸數據庫内的記錄與PubMed庫中已發表序列的引文間的鍊接,或蛋白質序列記錄與核苷酸序列庫中編碼它的核苷酸序列間的鍊接。
數據庫檢索
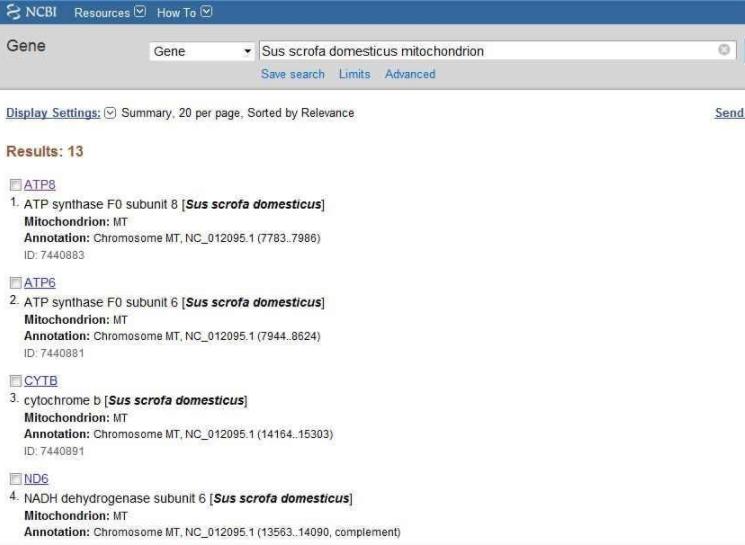
NCBI數據庫的檢索方法很簡單,在檢索框中輸入檢索詞,檢索詞間默認邏輯關系為AND,檢索規則基本同PubMed。圖2是顯示檢索結果頁面。
可以通過下拉菜單選擇記錄的顯示格式,通常選擇GenBank Report格式或FASTA Report格式。當選擇GenBank Report格式後,屏幕顯示較完整的基因記錄,其内容包括:基因位點(Locus)、基因定義(Definition)、基因存取号(Accession)、核酸編号(NID )、關鍵詞(Keywords)、來源(Source)、組織分類(Organism)、參考文獻(Reference)、著者(Author)、題目(Title)、期刊Journal)、Medline存取号(Medline)、序列特征(Features)、基因(Gene)、CDS(cDNA)、等位基因(Allele)對等的肽(Mat-Peptide)、計算堿基數(Base Count)、原序列(Origin)。而FASTA Report格式僅包括檢出序列的簡要特征描述。
●OMIM
孟德爾遺傳學(OMIM)數據庫是人類基因和基因疾病的目錄數據庫。該數據庫包括原文信息、圖片和參考信息,同時還可以鍊接到Entrez系統MEDLINE數據庫中相關文獻和序列信息。
相似性檢索
BLAST(Basic Local Alignment Search Tool)是用于序列相似性檢索的一個重要數據庫,是區分基因和基因特征的工具。該軟件能在15秒内完成整個DNA數據庫的序列檢索。BLAST記錄的相關度有明确的統計學解釋,以便更容易地将相關記錄與随機的數據庫記錄相區分。在NCBI主頁的左工具條中,點擊BLAST圖标,即進入BLAST主頁。
BLAST主頁提供了幾種BLAST檢索軟件。其中BLAST2.0是一種新的BLAST檢索工具,它在原有基礎上作了改進,運行速度更快,靈敏度更高,同時具有Gapped BLAST 和PSI-BLAST兩種軟件的新功能。Gapped BLAST允許在對準的序列中引入空位(堿基缺失或插入),引入空位(Gaps)意味着在比較兩個相關序列時不會出現中斷(Break)現象。這些空位對準的記分系統更能反映相關序列的類似程度。PSI-BLAST的全稱是Position-Specific Iterated BALST,即特殊位置重複BLAST,它提供了自動、易用的概貌(Profile)檢索,是查找序列同源的有效工具。
教育和訓練
NCBI通過贊助會議,研讨會,和系列演講來培養在應用于分子生物學和遺傳學的計算機領域的科學交流。一個科學訪問學者項目已經成立,來培養同外部科學家的合作。作為NIH内部的部分研究項目,也提供博士後工作位置。
美國國立醫學圖書館(NLM)于1988年11月4日建立國家生物技術信息中心(National Center of Biotechnology Information,簡稱NCBI)。該中心的主要任務為:
為儲存和分析分子生物學、生物化學、遺傳學知識創建自動化系統;從事研究基于計算機的信息處理過程的高級方法,用于分析生物學上重要的分子和化合物的結構與功能;促進生物學研究人員和醫護人員應用數據庫和軟件;努力協作以獲取世界範圍内的生物技術信息。
NCBI首先創建GenBank數據庫,在重點開發GenBank的同時,又于1991年開發了Entrez數據庫檢索系統。該系統整合了GenBank、EMBL、PIR和SWISS-PROT等數據庫的序列信息以及MEDLINE有關序列的文獻信息,并通過相關鍊接,将他們有機地結合在一起。NCBI還提供了其它數據庫,包括在線人類孟德爾遺傳(OMIM)、三維蛋白結構的分子模型數據庫(MMDB)、人類基因序列集成(UniGene)、人類基因組基因圖譜(GMHG)、生物門類(Toxonomy)等數據庫。圖1是NCBI分子生物學數據庫檢索主頁。